At the time of writing this post there is no built-in support for creating dynamic per recipient subscriptions for paginated reports if your report has any multi-value parameters. But there is a simple workaround that should enable you to set this up with minimal extra overhead.
Overview
The basic idea is to create a report just for your dynamic subscriptions that has a simple text parameter which you can then split based on some delimiter to pass to your “main” report.
The problem
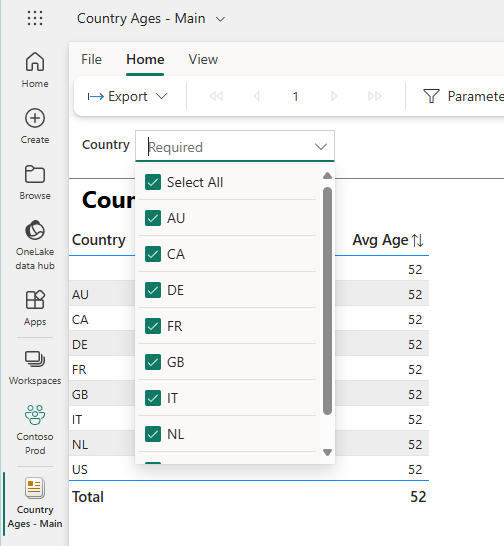
To test this, I created a simple report using some Contoso data which has a list of country codes and the average customer age in each country. The actual data is not important, but the fact that I have a required multi-value parameter means that when you try to create a dynamic subscription it will throw an error when the subscription runs. I’ll refer to this as the “main” report.
This is what the parameter for my “main” report looks like
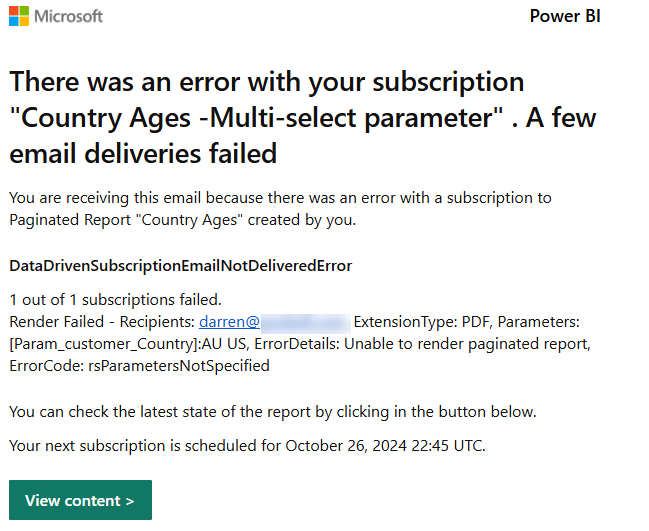
This is the sort of error that the subscription owner will see if you try to pass multiple values to the Country parameter:
The solution
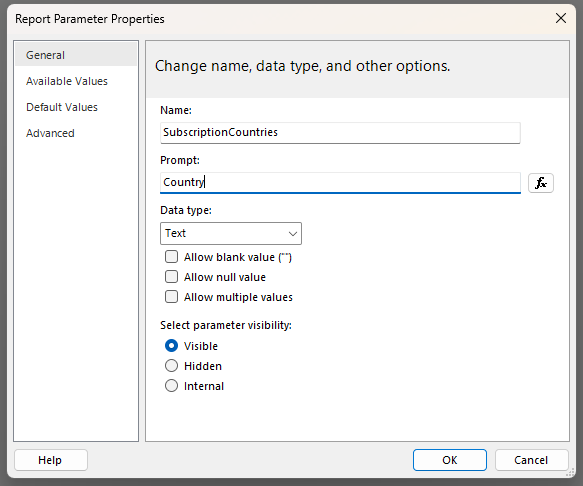
To work around this issue, I created a second report, which we will call the “subscription” report. I then created a local parameter which I called “SubscriptionCountries” so that I would know that this is the parameter in the “subscription” version of the report. You need to create one parameter in this report for each of the parameters in your “main” report.
Even though the Country parameter in the “main” report has the “Allow multiple values” option checked I did not select this in the “subscription” report and left it as a plain text parameter – this is the key to getting the subscription to work
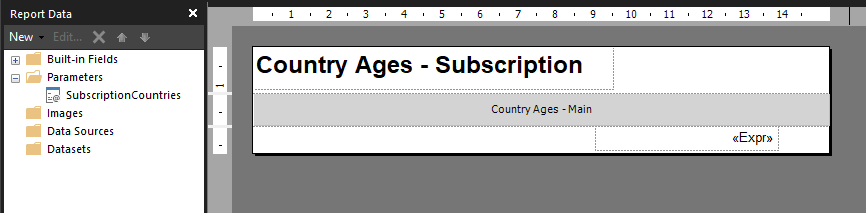
I then inserted a subreport and removed all the surrounding whitespace. I also made sure to configure the width of this report to be the same as the “main” version of the report. Then I configured the properties of this subreport to use the “main” version of the report.
I also had to setup the header and footer in the “subscription” report since subreports only render the body area of the report.
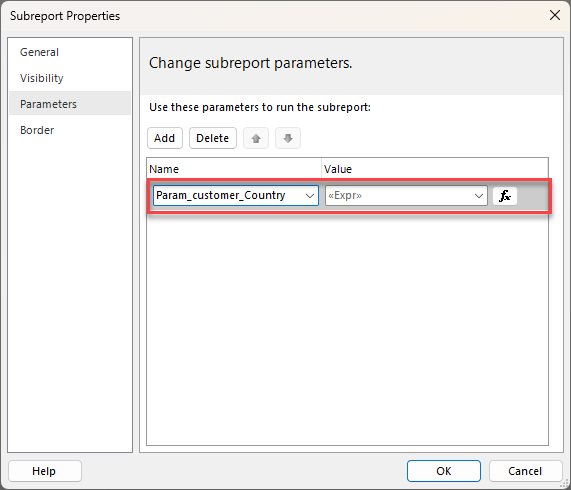
The next step was to configure the parameter properties for the subreport. For any parameters that are not multi-select you can just map these directly to the subscription version of the parameter. But for any multi-value parameters the trick is to set these using an expression.
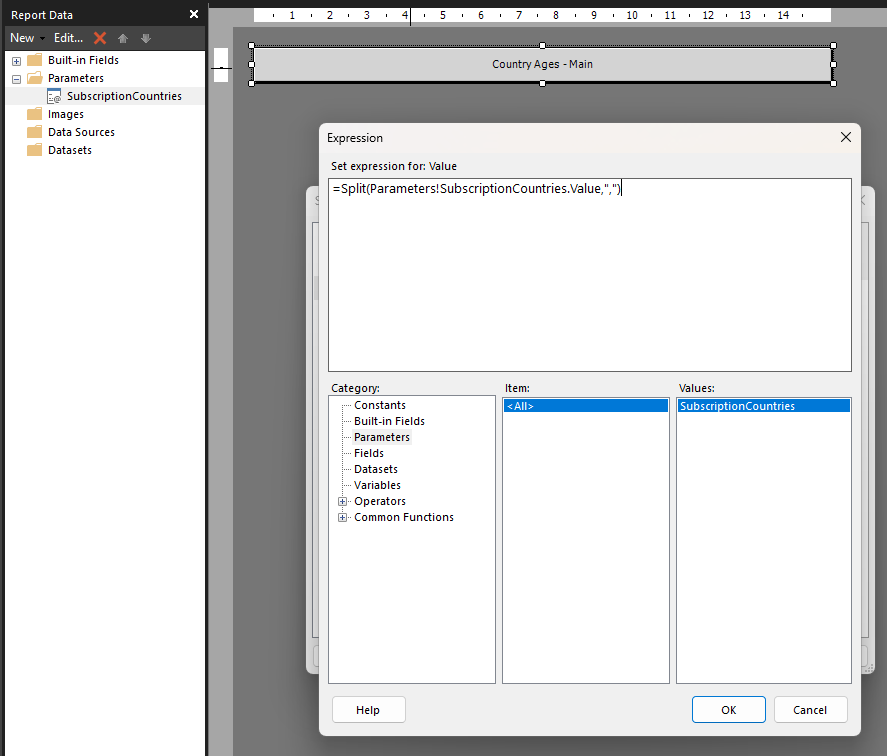
In my case I chose to pass the multiple values as a comma separated string, using the following expression, but if you wanted to use a different parameter like a semi-colon or pipe character you could do that.
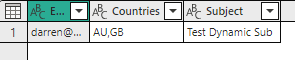
The rest is simple, I just created a semantic model that contained the multiple values as a comma separated string and then configured my dynamic per recipient subscription to use that value
Then when the subscription ran, I received the following email in my inbox
Conclusion
While it would be nicer if dynamic subscriptions had native support for multi-valued parameters at least this technique should unblock you with minimal extra work.
To keep your workspace “cleaner” I would suggest putting these special subscription versions of the reports in their own folder in your workspace.
In my last post I use SPN authentication, this time we are going to use the function mssparkutils.credentials.getToken() to get the authentication token for owner of the notebook.
NOTE: I’m still learning python and spark, so this may not be the best way of doing things, I’m just sharing what’s worked for me. Feel free to drop a comment if you see any areas that can be improved.
If you just want to see the full code listing without the explanations between the sections you can find it at the end of this post.
Extracting data from a REST API
from pyspark.sql.functions import *
import requests, os, datetime
from delta.tables import *
############################################################
# Authentication - Using owner authentication
############################################################
access_token = mssparkutils.credentials.getToken("https://analysis.windows.net/powerbi/api")
print('Successfully authenticated.')
############################################################
# Get Refreshables
############################################################
base_url = 'https://api.powerbi.com/v1.0/myorg/'
header = {'Authorization': f'Bearer {access_token}'}
refreshables_url = "admin/capacities/refreshables?$top=200"
refreshables_response = requests.get(base_url + refreshables_url, headers=header)
# write raw data to a json file
requestDate = datetime.datetime.now()
outputFilePath = "//lakehouse/default/Files/refreshables/top_200_{year}{month}{day}.json".format(year = requestDate.strftime("%Y"), month= requestDate.strftime("%m"), day=requestDate.strftime("%d"))
if not os.path.exists(os.path.dirname(outputFilePath)):
print("creating folder: " + os.path.dirname(outputFilePath))
os.makedirs(os.path.dirname(outputFilePath), exist_ok=True)
with open(outputFilePath, 'wb') as f:
f.write(refreshables_response.content)
To this point we have executed a call against the REST API and we have a response object in the refreshables_response variable. And then we’ve written the content property of that response out to a file using a binary write since the content property contains a byte array. What we want to do now is to read that byte array into a spark dataframe so that we can write it out to a table.
Converting a string to a dataframe
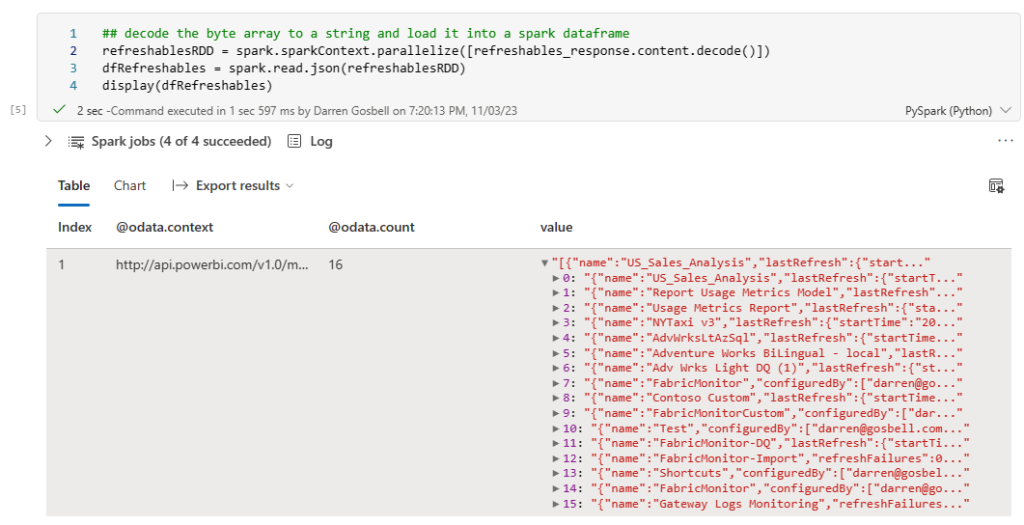
Spark does have a method which can read a json file into a spark dataframe, but it seems a bit silly to do that extra IO of reading the file off disk when I still have the data from that file in a variable in memory. You can do this by wrapping the string from the response content in a calling to the parallelize() method then wrapping that in a call to spark.read.json()
We are almost there, however if you use the display() method to have a look at the results you will see that the dataframe only has a single row with a value column that has an array in it.
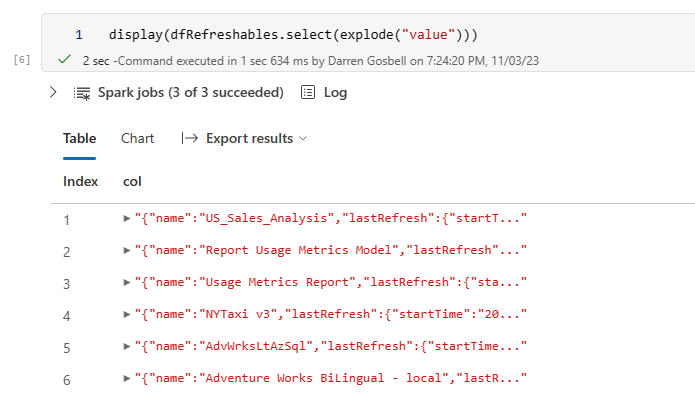
But ideally what we would like is a table with a row for each element in the array, not just a single row with the array in a column. To do this we can select from the dataframe and call the explode() method on the value column
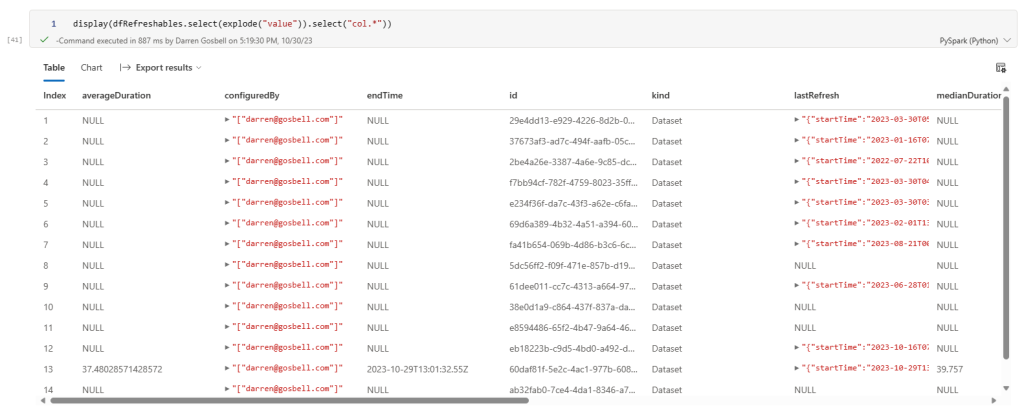
This is looking a bit better, but now we have a nested object inside a column called col and what I really want is to break each of the properties from those objects out into separate columns. And we can do that by added a .select(“col.*”) on the end of our exploded select.
That has successfully split out every property into its own column. If you want to get a subset of columns or list the columns in a certain order you can just reference them by name using a syntax like the following:
Now that I have a dataframe in the exact format that I want it is trivial to write this out to a delta table in my lakehouse by calling the .write() method on the dataframe
If all you want to do is to overwrite the data in your table each time you run your notebook then you can stop at this point. But what if you are doing an incremental load and you want to insert new records if they don’t already exist or update a record if the id is already in the table. In this case you can use the following code:
This code will check if the table already exists, if it doesn’t it uses the write method to create a new table. But if the table does exist, we then use the merge method to do an upsert operation.
The full code sample
The section below contains all of the code snippets from the above as a single block that you can paste into a cell in a Fabric notebook. When you run this it should:
Query the Power BI get Refreshables API.
Store the raw output in a json file in the Files portion of the attached lakehouse.
Write out this data to a delta table in the lakehouse.
from pyspark.sql.functions import *
import requests, os, datetime
from delta.tables import *
#########################################################################################
# Authentication - Using owner authentication
#########################################################################################
access_token = mssparkutils.credentials.getToken("https://analysis.windows.net/powerbi/api")
print('\nSuccessfully authenticated.')
#########################################################################################
# Get Refreshables
#########################################################################################
base_url = 'https://api.powerbi.com/v1.0/myorg/'
header = {'Authorization': f'Bearer {access_token}'}
refreshables_url = "admin/capacities/refreshables?$top=200"
refreshables_response = requests.get(base_url + refreshables_url, headers=header)
# write raw data to a json file
requestDate = datetime.datetime.now()
outputFilePath = "//lakehouse/default/Files/refreshables/top_200_{year}{month}{day}.json".format(year = requestDate.strftime("%Y"), month= requestDate.strftime("%m"), day=requestDate.strftime("%d"))
if not os.path.exists(os.path.dirname(outputFilePath)):
print("creating folder: " + os.path.dirname(outputFilePath))
os.makedirs(os.path.dirname(outputFilePath), exist_ok=True)
with open(outputFilePath, 'wb') as f:
f.write(refreshables_response.content)
refreshablesRDD = spark.sparkContext.parallelize([refreshables_response.content.decode()])
dfRefreshables = spark.read.json(refreshablesRDD)
dfRefreshables = dfRefreshables.select(explode("value")) \
.select("col.id",
"col.startTime",
"col.endTime",
"col.medianDuration",
"col.averageDuration",
"col.lastRefresh.status",
"col.lastRefresh.refreshType")
## write the spark dataframe out to a delta table
if spark.catalog.tableExists("refreshables"):
#get existing table
targetTable = DeltaTable.forName(spark,"refreshables")
#merge into table
(targetTable.alias("t")
.merge(dfRefreshables.alias("s"), "s.Id = t.Id")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
else:
# create workspace table
dfRefreshables.write.mode('overwrite').format("delta").saveAsTable("refreshables")
The introduction of Microsoft Fabric at the Build Conference last month has added a whole lot of new functionality that you can use. One of the new items we now have access to is a simple way of running Notebooks. And these Notebooks open up all sorts of interesting options for Data engineering, exploration and ingestion.
One of the things that this makes possible is to call a Power BI REST API and save the results into the Files section of a Fabric Lakehouse.
So lets look at an example of that calling the Get Refreshables API.
Setup
There are a couple of setup steps before you can run the script below.
Firstly, I’ve actually followed best practices here and used Azure Key Vault to secure all the secrets for my script rather than just hard coding them. I’ve added the following 3 secrets to my key vault:
FabricTenantId – my Power BI tenant ID
FabricClientId – the client ID for an SPN that I created to run this script
FabricClientSecret – the client secret for the SPN
I then gave my user access to read those secrets and because the notebook uses the identity of the owner when it executes this also works even when your setup a schedule for your notebook.
If you don’t have access to a key vault you could just hard code your values into this notebook.
Then I’ve created a Lakehouse in my workspace and created a refreshables folder under Files.
Once all that is done you can paste the following script into a new notebook and run it.
#########################################################################################
# Read secretes from Azure Key Vault
#########################################################################################
key_vault = "https://dgosbellKeyVault.vault.azure.net/"
tenant = mssparkutils.credentials.getSecret(key_vault , "FabricTenantId")
client = mssparkutils.credentials.getSecret(key_vault , "FabricClientId")
client_secret = mssparkutils.credentials.getSecret(key_vault , "FabricClientSecret")
#########################################################################################
# Authentication - Replace string variables with your relevant values
#########################################################################################
import json, requests, pandas as pd
import datetime
try:
from azure.identity import ClientSecretCredential
except Exception:
!pip install azure.identity
from azure.identity import ClientSecretCredential
# Generates the access token for the Service Principal
api = 'https://analysis.windows.net/powerbi/api/.default'
auth = ClientSecretCredential(authority = 'https://login.microsoftonline.com/',
tenant_id = tenant,
client_id = client,
client_secret = client_secret)
access_token = auth.get_token(api)
access_token = access_token.token
print('\nSuccessfully authenticated.')
#########################################################################################
# Get Refreshables
#########################################################################################
base_url = 'https://api.powerbi.com/v1.0/myorg/'
header = {'Authorization': f'Bearer {access_token}'}
refreshables_url = "admin/capacities/refreshables?$top=200"
print(refreshables_url)
refreshables_response = requests.get(base_url + refreshables_url, headers=header)
# write raw data to a json file
with open("/lakehouse/default/Files/refreshables/top200.json", 'wb') as f:
f.write(refreshables_response.content)
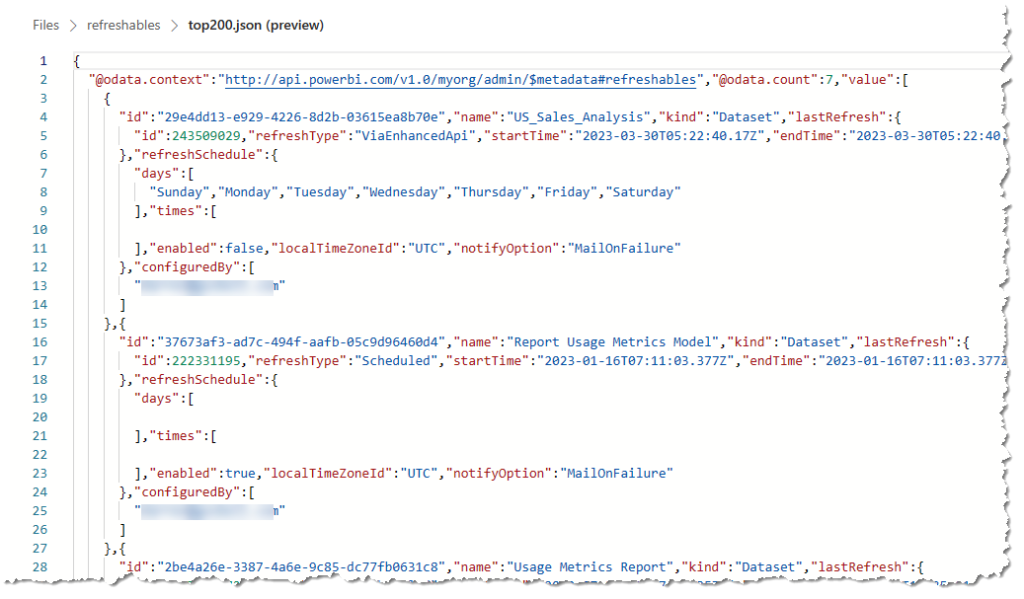
The Output
If we then open our lakehouse and have a look at the file that was generated, we can see the data returned from our API call.
Conclusion
Most of the script was just involved in getting the authentication working and the core portion that then calls the REST API was relatively simple.
This is all relatively new to me and I’m still learning about Python and Notebooks, so if you see anything where I’m not doing things the “right way” feel free to point them out. I’m planning to do some more Notebook related posts in the future. I’m particularly interested in pushing data into delta tables and then building a Power BI dataset in Direct Lake mode, so stay tuned for that.
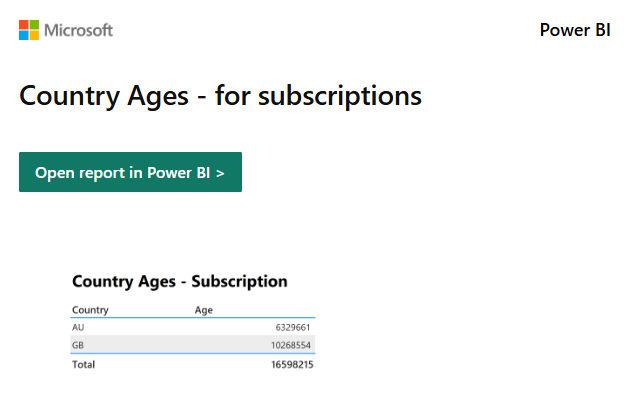
Recent Comments